基于文心一言与多模态大模型的语音交互无人机
基于文心一言与多模态大模型的语音交互无人机
第一部分 四个模块
A.语言识别模块——听得见
借助开源语言识别模块,结合文心一言LLM进行修正,将语言指令转换为文字指令。
B.文字生成控制代码模块——听得懂
通过预训练与知识集的形式,指导文心一言LLM控制无人机,将文字指令转化成可直接执行的控制代码。
C.目标识别与检测模块——看得懂
借助开源多模态大模型Recognize Anything Model(RAM) 识别图像环境中物体,返回存在物体的标签。
借助GroundingDINO模型对特定目标物体在图像中划分定位,为无人机飞行提供目标。
D.物体定位与追踪模块——找得到
距离估计:使用Tello头部的单目摄像头,调用开源
GLPN模型进行单目深度估计,获得单目深度图像,从而判断无人机方位。偏转角度估计:创新性地利用偏离角在相机视场角中的占比,进行角度估计
第二部分 具体实验内容
1.实验背景:CoT思维链
关于CoT(Chain of Thought):
随着LLM的发展,其强大的文字生成能力让其在各个领域得到了广泛的应用。但在面对具体的复杂任务时,往往因为缺乏合适的思维链引导,使其无法完全发挥出其强大的推理能力与上下文学习能力,进而降低任务的完成成功率。
所以,如今有众多科研工作者发现的新的方向——CoT,通过设计精巧的思维链,将一个复杂任务,按照类人思维方式,分解成不同子任务,依次解决,即可大幅度提高任务的完成率。
这一点在我们的任务中就得到很好的体现,我们也借此思路,针对无人机的寻物任务,设计了完整的CoT,大大提高寻物成功率。
2. 实验初期——直接执行任务——失败
在实验初始阶段,当部署调试完成各种模型后,编写完各种可执行任务函数,依次写入文心一言的prompt文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
想象一下,我是一个配备了摄像头和深度传感器的无人机。我正在尝试执行一项任务,您应该通过向我发送命令来帮助我。你只能给我以下命令:
在任何给定时间点,您都具有以下能力,每种能力都由唯一的标签标识。您还需要输出某些请求的代码。
问题:您可以向我提出一个澄清问题,只要您明确指出“问题”即可。
代码:
```python
这里输出达到预期目标的代码命令。
```
注意,我只要你输出代码,其他什么都不要说!我需要你的回答可以直接用来执行,不允许猜测我的未来可能目的与任务,每次只需要给出针对此次任务的代码即可
环境包含一架无人机和几个物体。除了无人机之外,没有任何物体是可移动的。在代码中,我们可以使用以下命令。您不得使用任何其他假设函数。
tello.takeoff() - 起飞无人机。
tello.land() - 降落无人机。
tello.forward(distance) - 向前移动distance米,注意,distance的单位是m,你可以更改distance的值,来前进不同距离
tello.get_image() - 获取无人机拍摄图像,用于后续识别
tello.get_drone_state() - 获得无人机状态
tello.get_objects() - 对无人机此时获得的图片进行对象检测,返回一个所检测到的对象列表obj_name_list, 这个列表是
tello.ob_objects_llm() - 返回格式化后的目标信息列表 final_result,其中每个元素都是包含目标名称、相机距离和角度的元组。
tello.turn(degrees) - 无人机旋转degrees度,degrees是角度值,当degrees为负时,无人机左转,当degrees为正时,无人机右转
当我们企图直接一步到位完成任务:“帮我找一下苹果”
往往LLM返回的可执行代码均会出现各式各样的逻辑错误,无法完成任务。
结论:目前对于文心一言而言,不能完成此类复杂任务的直接推理与生成工作
3. 实验中期——引入CoT对话——分解任务——成功
在查阅相关项目与论文资料后,我们决定引入CoT方法,将寻物任务分解为多个子任务,利用文心一言的上下文理解能力与推理能力,引导其生成正确的可执行代码。
最终,我们针对我们的实际情况,将寻物任务分解如下:
- 请告诉我图片中有什么?——引导LLM获取图像,利用RAM模型获取图片中所有物体的文字标签
- 请告诉我图片中物体的具体位置?——引导LLM根据所获标签,利用
GroundingDINO模型对各种物体进行图像中的位置框定,并依靠编写好的深度估计与角度估计方法,获取所有物体对应的具体方位。 - 请帮我找到A。——引导
LLM在之前获取的所有方位信息中选取目标物体方位,生成寻物代码,完成任务。
以下是实际操作效果:
实际实验场景:

STEP1:“请告诉我图片里有什么”
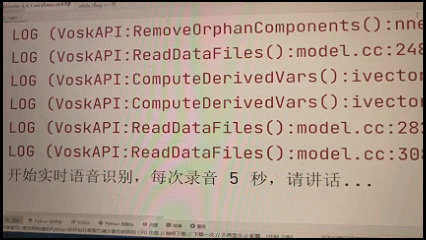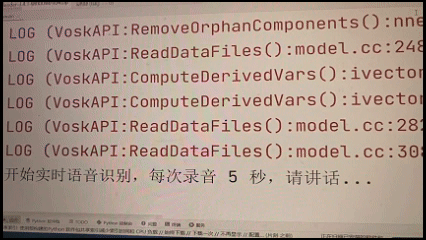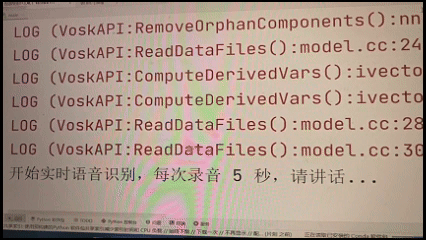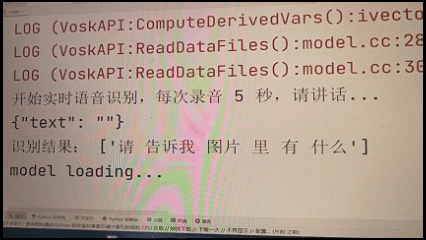
LLM生成代码调用RAM模型返回如下标签:
1
tello.get_objects()

STEP2:请告诉我图片中物体的具体位置?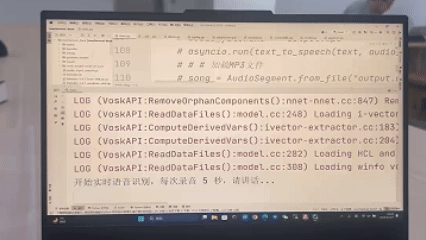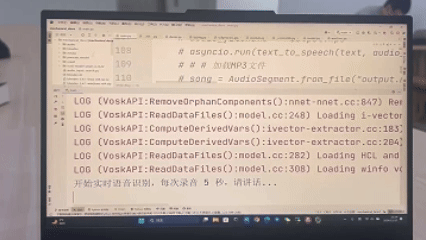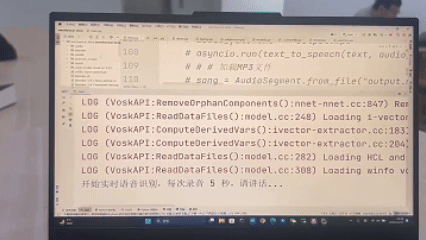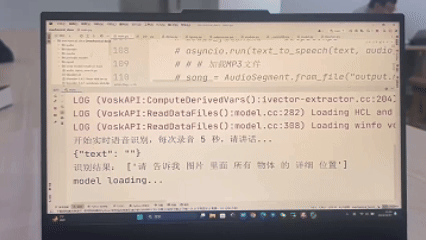
1
tello.ob_objects_llm()
LLM借助GroundingDINO模型对特定目标物体在图像中划分定位,结果如下:

- LLM利用距离与角度估计算法,返回以下方位信息:

STEP3:”我想吃水果,请帮我找一下“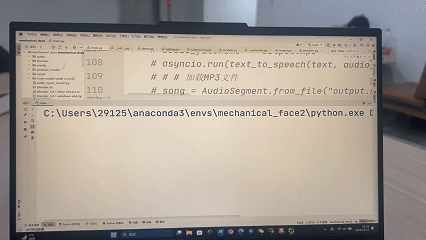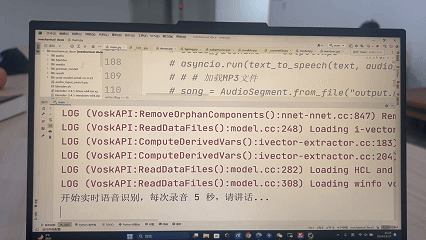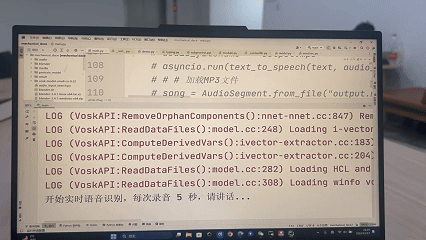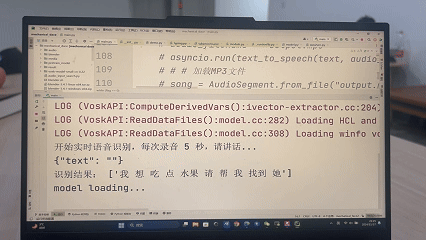
LLM理解需求,推理判定用户目标物体为视场中的apple,利用记忆的apple具体方位,生成相应的无人机寻物移动代码
1 2 3
tello.takeoff() tello.turn(-7) tello.forward(1.52)
- 无人机顺利依次完成起飞、调整方位角、前进特定距离以及降落的操作,成功降落到目标物体苹果附近。

4. 实验后期——整合CoT进入prompt——成功
虽然已经可以成功完成寻物任务,但每次进行人为的CoT引导,还是略显麻烦。
所以我们尝试教会LLM针对寻物问题的思维链方式,使其自己能自主完成这样的思维过程
只需要将方案写入prompt文件——教会LLM使用思维链
1 2 3 4 5 6 7 8
当然,还会有一些复杂的综合任务,比如我直接问你:请帮我寻找苹果(apple) 你需要先起飞tello.takeoff(), 使用tello.get_objects(),得到对象列表obj_name_list,如果其中没有苹果(apple), 你可以让机身旋转55度,然后再次使用tello.get_objects(), 直到你得到了苹果(apple)的标签,说明现在你前方有苹果(apple) 此时你可以使用tello.ob_objects_llm(apple) 得到目标物体(苹果)的具体位置,(注意,你在函数tello.ob_objects_llm()中填入的一定是英文标签,如果我给你的是中文标签,你需要在生成代码时主动翻译为英文标签) 之后和上一个示例一样,使用tello.forward(distance)和tello.turn(degrees)来完成任务 距离以米为单位,方向角以相对于无人机方向的度数为单位。
在这样的引导下,LLM自动生成了如下的寻物代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
tello.takeoff()
target = "apple"
while True:
# 获取当前视野中的物体列表
obj_name_list = tello.get_objects()
#打印物体列表
print(obj_name_list)
# 检查"target"是否在物体列表中
if target in obj_name_list:
# 如果找到"apple",获取其位置信息
final_result = tello.ob_objects_llm(target)
#打印位置信息
print(final_result)
print("找到了taget")
# 遍历位置信息,找到"target"的距离和角度
for obj_name, distance, degrees in final_result:
if obj_name == target:
# 根据得到的角度调整无人机的方向
tello.turn(degrees)
# 根据得到的距离让无人机前进到目标位置
tello.forward(distance)
# 找到并飞向"target"后,退出循环
break
break
else:
# 如果没有找到"target",则让无人机旋转90度后继续搜索
tello.turn(55)
print("未找到target")
# 如果需要,可以在此处添加降落无人机的命令
tello.land()
接下来,请观看无人机在各种寻物任务中的表现,只需要说出你想找的物体,即可自动开始搜寻——可谓百发百中弹无虚发
充分发挥了LLM的推理能力与多模态大模型的图像识别能力
“帮我找一下苹果”

“我想看书,帮我找一下”

“帮我找一下笔记本电脑”

“我想喝可乐,帮我找一下”

第三部分 问题与困难
- 模型运行较慢,而无人机在15s无指令后自动降落,并且官方心跳包有bug,造成大多数时候实验无法从头到尾流程进行,往往在最后一步LLM返回代码时无人机已经断联或降落,但可以将返回代码复制后直接运行,效果一致。
- 无人机飞行不稳定,容易飘忽不定,并且缺乏精确惯导单元,内部算法依靠图像纹路判断距离等,一旦环境中过于单调,就会报错
No IMU或者自动降落,其实就是无法判断方位和距离了。即使无人机没有报错,其飞行距离也极其不准确,所以也会出现上述实验中的撞击事件。
第四部分 未来工作
- 针对更多的场景,设计不同的prompt提示文件与CoT思维链方法,使得LLM可以控制无人机适用于多样化的工作场景。
- 尝试使用其他大语言模型进行项目效果对比,或者利用最新的一体式多模态大语言模型进行无人机的控制工作。
- 在搭载深度相机的无人机上进行项目部署尝试。
第五部分 分工
| 任务 | A | B | C |
|---|---|---|---|
| 语音转文字模块 | √ | ||
| 文字生成控制代码模块 | √ | ||
| 目标识别与定位模块 | √ | ||
| 单目深度估计模块 | √ | ||
| 4模块集成与仿真验证 | √ | √ | √ |
| 实机部署与调试验证 | √ | √ | √ |
| 实验任务设计与测试 | √ | ||
| 开题PPT制作 | √ | ||
| 验收PPT制作 | √ | √ | |
| 代码、材料整理开源与文字撰写 | √ | ||
| 视频剪辑与处理 | √ |
第六部分 参考文献
- Huang, X., Huang, Y. J., Zhang, Y., Tian, W., Feng, R., Zhang, Y., … & Zhang, L. (2023). Open-set image tagging with multi-grained text supervision. arXiv e-prints, arXiv-2310.
- Zhang, Y., Huang, X., Ma, J., Li, Z., Luo, Z., Xie, Y., … & Zhang, L. (2024). Recognize anything: A strong image tagging model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1724-1732).
- Huang, X., Zhang, Y., Ma, J., Tian, W., Feng, R., Zhang, Y., … & Zhang, L. (2023). Tag2text: Guiding vision-language model via image tagging. arXiv preprint arXiv:2303.05657.
- Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., … & Zhang, L. (2023). Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499.
- Kim, D., Ka, W., Ahn, P., Joo, D., Chun, S., & Kim, J. (2022). Global-local path networks for monocular depth estimation with vertical cutdepth. arXiv preprint arXiv:2201.07436.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35, 24824-24837.
- Vemprala, S., Bonatti, R., Bucker, A., & Kapoor, A. (2023). Chatgpt for robotics: Design principles and model abilities. 2023. Published by Microsoft.
- https://aistudio.baidu.com/projectdetail/7158159?searchKeyword=%E7%94%A8%E6%96%87%E5%BF%83%E5%A4%A7%E6%A8%A1%E5%9E%8B%E9%A3%9E%E9%A3%9E%E6%9C%BA&searchTab=ALL