Matrix Derivation
Matrix Derivation
Context
本学期各门课程使用到矩阵,包括《人工智能》、《现代控制理论》、《组合导航原理》等等。是有必要恶补一下我贫瘠的数学基础了。此文暂且总结记录一下关于标量对矩阵的导数求解方法,至于矩阵对矩阵的导数,先搁置一边(lazy~)。
Mathematic Symbols
| 符号 | 表义 |
|---|---|
| $x$ | 标量 |
| $\boldsymbol{x}$ | (列)向量 |
| $X$ | 矩阵 |
Definition
标量$f$对矩阵$X$的导数,定义为:
\[\frac{\partial f}{\partial X}=\left[ \frac{\partial f}{\partial X_{ij}} \right]\]其实就是$f$对$X$逐个元素求导,然后再排列成矩阵的样子。本质上就是复合函数逐个求偏导,但因为我们lazy,不想拆开放,所以是有必要开发一下矩阵求导的tricks。
- 一元微积分中的导数与微分
- \[df=f^{\prime}(x)dx\]
- 多元微积分中梯度与微分
- \[df=\sum_{i=1}^n{\frac{\partial f}{\partial x_i}dx_i}=\left( \frac{\partial f}{\partial \boldsymbol{x}} \right) ^Td\boldsymbol{x}\]
- 建立矩阵导数与微分的联系
- \[df=\sum_{i=1}^m{\sum_{j=1}^n{\frac{\partial f}{\partial X_{ij}}dX_{ij}=tr\left( \left( \frac{\partial f}{\partial X} \right) ^{\boldsymbol{T}}dX \right)}}\]
其中利用了trace的性质
\[\mathrm{tr}\left( A^TB \right) =\sum_{i,j}^{}{A_{i,j}B_{i,j}}\]Matrix Derivation Principles
加减法:$d(X\pm Y)=dX\pm dY$;
乘法:$d(XY)=(dX)Y+XdY$;
转置:$d(X^T)=(dX)^T$;
迹:$d\text{tr}(X)=\text{tr}(dX)$;
逆:$dX^{-1}=-X^{-1}dXX^{-1}$,证明如下
\[d(XX^{-1})=dI=(dX)X^{-1}+Xd(X^{-1})=0\\ \Rightarrow dX^{-1}=-X^{-1}dXX^{-1}\]渲染失败了换图片吧:
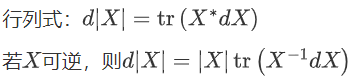
逐元素乘法:$d\left(X\odot Y\right)=d X\odot Y+X\odot dY$
逐元素函数:$d\sigma(X)=\sigma^{\prime}(X)\odot dX$,其中$\sigma^{\prime}(X)=[\sigma^{\prime}(X_{ij})]$
Trace Tricks
- 标量套上trace:$a=\operatorname{tr}(a)$
- 转置:$\operatorname{tr}(A^T)=\operatorname{tr}(A)$
- 线性:$\operatorname{tr}(A\pm B)=\operatorname{tr}(A)\pm \operatorname{tr}(B)$
- 矩阵乘法交换:$\operatorname{tr}(AB)=\operatorname{tr}(BA)$
- 矩阵乘法/逐元素乘法交换:$\operatorname{tr}(A^T(B\odot C))=\operatorname{(A\odot B)^T C}$,其中$A,B,C$尺寸相同,两侧均等于$\sum_{i,j}^{}{A_{ij}B_{ij}C_{ij}}$
Derivation Methods Conclusion
不难看出,若标量函数$f$是矩阵$X$经加减乘、逆、行列式、逐元素函数等运算构成,则使用相应的运算法则对$f$微分,然后给它“穿衣服”——trace trick,套上trace然后将其他项交换到$dX$左侧,对照$df=tr\left( \left( \frac{\partial f}{\partial X} \right) ^{\boldsymbol{T}}dX \right)$即可得到导数$\frac{\partial f}{\partial X}$。
Tips: about the chain principle
不能随意沿用标量中的链式法则
必须从本质微分入手,例如
\[\begin{aligned} &\text { 最常见的情形是 } Y=A X B \text { ,此时 }\\ &\begin{aligned} & d f=\operatorname{tr}\left(\frac{\partial f}{\partial Y}^T d Y\right)=\operatorname{tr}\left(\frac{\partial f}{\partial Y}^T A d X B\right)=\operatorname{tr}\left(B \frac{\partial f}{\partial Y}^T A d X\right) \\ & =\operatorname{tr}\left(\left(A^T \frac{\partial f}{\partial Y} B^T\right)^T d X\right) \end{aligned} \end{aligned}\]Common Examples
e.g.1(fake chain principle)
$f=\operatorname{tr}\left(Y^T M Y\right), Y=\sigma(W X)$ ,求 $\frac{\partial f}{\partial X}$ 。其中 $W$ 是 $l \times m$ 矩阵, $X$ 是 $m \times n$ 矩阵, $Y$是 $l \times n$ 矩阵, $M$ 是 $l \times l$ 对称矩阵, $\sigma$ 是逐元素函数, $f$ 是标量。
解:
先求 $\frac{\partial f}{\partial Y}$ ,求微分,使用矩阵乘法、转置法则:
\[\begin{aligned} & d f=\operatorname{tr}\left((d Y)^T M Y\right)+\operatorname{tr}\left(Y^T M d Y\right)=\operatorname{tr}\left(Y^T M^T d Y\right)+\operatorname{tr}\left(Y^T M d Y\right) \\ & =\operatorname{tr}\left(Y^T\left(M+M^T\right) d Y\right) \end{aligned}\],对照导数与微分的联系,得到 $\frac{\partial f}{\partial Y}=\left(M+M^T\right) Y=2 M Y$ ,注意这里M是对称矩阵 。为求 $\frac{\partial f}{\partial X}$ ,写出 $d f=\operatorname{tr}\left({\frac{\partial f}{\partial Y}}^T d Y\right)$ ,再将$dY$用$dX$表示出来代入,并使用矩阵乘法/逐元素乘法交换: $d f=\operatorname{tr}\left(\frac{\partial f}{\partial Y}{ }^T\left(\sigma^{\prime}(W X) \odot(W d X)\right)\right)=\operatorname{tr}\left(\left(\frac{\partial f}{\partial Y} \odot \sigma^{\prime}(W X)\right)^T W d X\right)$ ,对照导数与微分的联系,得到
\[\frac{\partial f}{\partial X}=W^T\left(\frac{\partial f}{\partial Y} \odot \sigma^{\prime}(W X)\right)=W^T\left((2 M \sigma(W X)) \odot \sigma^{\prime}(W X)\right)\]e.g.2 Linear Regression
$l=|X \boldsymbol{w}-\boldsymbol{y}|^2$ ,求 $\boldsymbol{w}$ 的最小二乘估计,即求 $\frac{\partial l}{\partial \boldsymbol{w}}$ 的零点。其中 $\boldsymbol{y}$ 是 $m \times 1$ 列向量, $X$ 是 $m \times n$ 矩阵,$ \boldsymbol{w}$ 是 $n \times 1$ 列向量, $l$ 是标量。
解:
这是标量对向量的导数,不过可以把向量看做矩阵的特例。先将向量模平方改写成向量与自身的内积: $l=(X \boldsymbol{w}-\boldsymbol{y})^T(X \boldsymbol{w}-\boldsymbol{y})$ ,求微分,使用矩阵乘法、转置等法则: $d l=(X d \boldsymbol{w})^T(X \boldsymbol{w}-\boldsymbol{y})+(X \boldsymbol{w}-\boldsymbol{y})^T(X d \boldsymbol{w})=2(X \boldsymbol{w}-\boldsymbol{y})^T X d \boldsymbol{w}$ ,注意这里 $X d \boldsymbol{w}$和 $X \boldsymbol{w}-\boldsymbol{y}$ 是向量,两个向量的内积满足 $\boldsymbol{u}^T \boldsymbol{v}=\boldsymbol{v}^T \boldsymbol{u}$ 。对照导数与微分的联系 $d l=\frac{\partial l}{\partial \boldsymbol{w}}^T d \boldsymbol{w}$ ,得到 $\frac{\partial l}{\partial \boldsymbol{w}}=2 X^T(X \boldsymbol{w}-\boldsymbol{y}) 。 \frac{\partial l}{\partial \boldsymbol{w}}=0$ 即 $X^T X \boldsymbol{w}=X^T \boldsymbol{y}$ ,得到 $\boldsymbol{w}$ 的最小二乘估计为 $\boldsymbol{w}=\left(X^T X\right)^{-1} X^T \boldsymbol{y}$。